Deep Deterministic Policy Gradient (DDPG)#
off-policy deterministicPaper: Continuous Control with Deep Reinforcement Learning
Pseudocode#
Configuration#
@dataclass
class ActorNoiseConfig:
"""
Configuration for the Ornstein-Uhlenbeck process used to add noise to actions during training.
Attributes:
mu (float): Long-running mean of the noise process.
theta (float): Speed of mean reversion.
sigma (float): Volatility (standard deviation of noise).
dt (float): Time step size.
x0 (float): Initial state of the noise process (optional).
"""
mu: float = 0
theta: float = 0.15
sigma: float = 0.2
dt: float = 1e-2
x0: float | None = None
@dataclass
class DDPGActorConfig:
"""
Configuration for the DDPG actor network.
Attributes:
arch (type): Class for the actor network architecture.
actor_type (type): Actor class to be used.
has_target (bool): Whether the actor maintains a target network.
"""
arch: type = ActorNet
actor_type: type = DDPGActor
has_target: bool = True
@dataclass
class DDPGCriticConfig:
"""
Configuration for the DDPG critic network.
Attributes:
arch (type): Class for the critic network architecture.
critic_type (type): Critic class to be used.
n_members (int): Number of critic networks to use in the ensemble.
loss (str): Name of the loss function to use ( "MSELoss").
policy_delay (int): Number of critic updates per actor update.
tau (float): Soft update coefficient for Polyak averaging.
"""
arch: type = CriticNet
critic_type: type = DDPGCritic
n_members: int = 1
@dataclass
class DDPGConfig:
"""
Top-level configuration for the Deep Deterministic Policy Gradient (DDPG) agent.
Attributes:
name (str): Name of the algorithm.
noise (ActorNoiseConfig): Noise configuration for exploration.
loss (str): Loss function for critic training.
policy_delay (int): How often to update the actor policy.
tau (float): Soft update coefficient for target networks.
actor (DDPGActorConfig): Configuration for the actor.
critic (DDPGCriticConfig): Configuration for the critic.
"""
name: str = "ddpg"
noise: ActorNoiseConfig = field(default_factory=ActorNoiseConfig)
loss: str = "MSELoss"
policy_delay: int = 1
tau: float = 0.005
actor: DDPGActorConfig = field(default_factory=DDPGActorConfig)
critic: DDPGCriticConfig = field(default_factory=DDPGCriticConfig)
def __post_init__(self) -> None:
"""
Converts `noise` from a dictionary to an ActorNoiseConfig if needed.
Useful when loading from a JSON or dict-based config file.
Args:
None
Returns:
None
"""
if isinstance(self.noise, dict):
self.noise = ActorNoiseConfig(**self.noise)
UML Diagram#
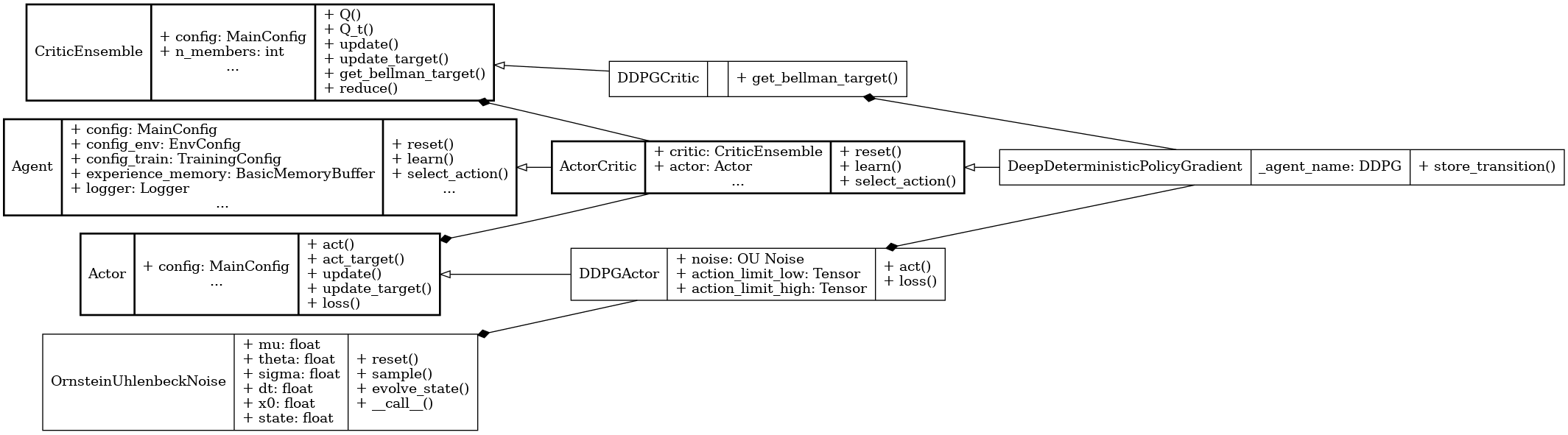
UML diagram for the DDPG algorithm.#
We use the UML diagram to illustrate the relationships between the classes in our DDPG implementation.
The diagram shows how the DDPGActor and DDPGCritic classes inherit from the base classes Actor and CriticEnsemble, respectively. DeepDeterministicPolicyGradient class also inherits from ActorCritic class which inherits from Agent.
We illustrate each class's crucial attributes and methods for DDPG. Specifically:
get_bellman_target() method in DDPGCritic class is implemented to compute the Bellman target for the critic in DDPG style.
act() and loss() methods in DDPGActor class are implemented to act in DDPG style and update the actor's policy.
Exploration Noise#
We use the OrnsteinUhlenbeckNoise class to inject noise into the actor's actions to encourage exploration. This noise process is commonly used in DDPG for continuous action spaces due to its temporal correlation.
- class objectrl.models.ddpg.OrnsteinUhlenbeckNoise(dim_act: int, mu: float = 0, theta: float = 0.15, sigma: float = 0.2, dt: float = 0.01, x0: float | None = None)[source]#
Bases:
objectImplements Ornstein-Uhlenbeck process to generate temporally correlated noise. Commonly used in DDPG to add exploration noise to continuous actions.
- Parameters:
dim_act (int) – Shape of the action space.
mu (float) – Long-running mean.
theta (float) – Speed of mean reversion.
sigma (float) – Volatility (standard deviation).
dt (float) – Time step size.
x0 (float, optional) – Initial value of the process.
Classes#
- class objectrl.models.ddpg.DDPGActor(config: MainConfig, dim_state: int, dim_act: int)[source]#
Bases:
ActorDDPG actor module that produces actions and applies OU noise during training.
- interaction_iter#
Counter for interaction steps.
- Type:
int
- sampling_rate#
Frequency of head sampling for posterior sampling.
- Type:
int
- idx_active_critic#
Index of the currently active critic head.
- Type:
int
- is_episode_end#
Flag indicating if the current episode has ended.
- Type:
bool
- __init__(config: MainConfig, dim_state: int, dim_act: int) None[source]#
Initializes the Actor.
- Parameters:
config (MainConfig) – Configuration dataclass instance.
dim_state (int) – Dimension of observation space.
dim_act (int) – Dimension of action space.
- Returns:
None
- act(state: Tensor, is_training: bool = True) dict[source]#
Produces an action given a state. Adds noise during training.
- Parameters:
state (torch.Tensor) – The input state.
is_training (bool) – Whether to add exploration noise.
- Returns:
Dictionary containing ‘action’ and ‘action_wo_noise’.
- Return type:
dict
- loss(state: Tensor, critics: CriticEnsemble) Tensor[source]#
Computes the loss for the actor by maximizing the critic’s Q-value.
- Parameters:
state (torch.Tensor) – Batch of input states.
critics (CriticEnsemble) – Critic network(s).
- Returns:
Actor loss (negative Q-value).
- Return type:
torch.Tensor
- class objectrl.models.ddpg.DDPGCritic(config: MainConfig, dim_state: int, dim_act: int)[source]#
Bases:
CriticEnsembleDDPG critic module implementing Q-value estimation and Bellman target computation.
- loss#
Loss function for training.
- Type:
- gamma#
Discount factor for future rewards.
- Type:
float
- __init__(config: MainConfig, dim_state: int, dim_act: int) None[source]#
Initialize the critic ensemble.
- Parameters:
config (MainConfig) – Configuration object with model parameters.
dim_state (int) – Dimension of the state space.
dim_act (int) – Dimension of the action space.
- Returns:
None
- get_bellman_target(reward: Tensor, next_state: Tensor, done: Tensor, actor: DDPGActor) Tensor[source]#
Computes the Bellman target for critic training.
- Parameters:
reward (torch.Tensor) – Reward signal.
next_state (torch.Tensor) – Next state.
done (torch.Tensor) – Done flag (1 if terminal, else 0).
actor (DDPGActor) – Actor network (used for target action).
- Returns:
Bellman target (y).
- Return type:
torch.Tensor
- class objectrl.models.ddpg.DeepDeterministicPolicyGradient(config: MainConfig, critic_type: type = <class 'objectrl.models.ddpg.DDPGCritic'>, actor_type: type = <class 'objectrl.models.ddpg.DDPGActor'>)[source]#
Bases:
ActorCriticFull DDPG agent, combining actor and critic with target networks and experience replay. Lillicrap et al. (2015): Continuous Control with Deep Reinforcement Learning
- _agent_name = 'DDPG'#
- __init__(config: MainConfig, critic_type: type = <class 'objectrl.models.ddpg.DDPGCritic'>, actor_type: type = <class 'objectrl.models.ddpg.DDPGActor'>) None[source]#
Initializes DDPG agent.
- Parameters:
config (MainConfig) – Configuration dataclass instance.
critic_type (type) – Critic class type.
actor_type (type) – Actor class type.
- Returns:
None