Optimistic Actor-Critic (OAC)#
optimistic explorationPaper: Better Exploration with Optimistic Actor-Critic
Pseudocode#
Configuration#
@dataclass
class OACActorConfig:
"""
Configuration for the OAC Actor network.
Attributes:
arch (type): The architecture class used for the actor network.
actor_type (type): The actor implementation class (OACActor).
"""
arch: type = ActorNetProbabilistic
actor_type: type = OACActor
@dataclass
class OACCriticConfig:
"""
Configuration for the OAC Critic network.
Attributes:
arch (type): The architecture class used for the critic network.
critic_type (type): The critic implementation class ( OACCritic).
"""
arch: type = CriticNet
critic_type: type = OACCritic
@dataclass
class CriticNoiseConfig:
"""
Configuration for Gaussian noise added to critic target actions.
Attributes:
sigma_target (float): Standard deviation of Gaussian noise.
noise_clamp (float): Maximum absolute value to clamp the noise.
"""
sigma_target: float = math.sqrt(0.2)
noise_clamp: float = 0.5
@dataclass
class ActorExplorationConfig:
"""
Configuration for optimistic exploration noise in OAC.
Attributes:
delta (float): Uncertainty scaling factor for exploration.
beta_ub (float): Upper bound multiplier on critic std deviation.
"""
delta: float = 0.1
beta_ub: float = 4.66
@dataclass
class OACConfig:
"""
Top-level configuration for the OAC (Optimistic Actor Critic) agent.
Attributes:
name (str): Agent name identifier.
loss (str): Loss function used for training.
policy_delay (int): Number of critic updates per actor update.
tau (float): Polyak averaging coefficient for target networks.
noise (CriticNoiseConfig): Configuration for Gaussian target noise.
exploration (ActorExplorationConfig): Config for exploration noise.
target_entropy (float or None): Target policy entropy.
alpha (float): Entropy regularization coefficient.
actor (OACActorConfig): Actor network configuration.
critic (OACCriticConfig): Critic network configuration.
"""
name: str = "oac"
loss: str = "MSELoss"
policy_delay: int = 1
tau: float = 0.005
noise: CriticNoiseConfig = field(default_factory=CriticNoiseConfig)
exploration: ActorExplorationConfig = field(default_factory=ActorExplorationConfig)
target_entropy: float | None = None
alpha: float = 1.0
actor: OACActorConfig = field(default_factory=OACActorConfig)
critic: OACCriticConfig = field(default_factory=OACCriticConfig)
def __post_init__(self):
if isinstance(self.noise, dict):
self.noise = CriticNoiseConfig(**self.noise)
if isinstance(self.exploration, dict):
self.exploration = ActorExplorationConfig(**self.exploration)
UML Diagram#
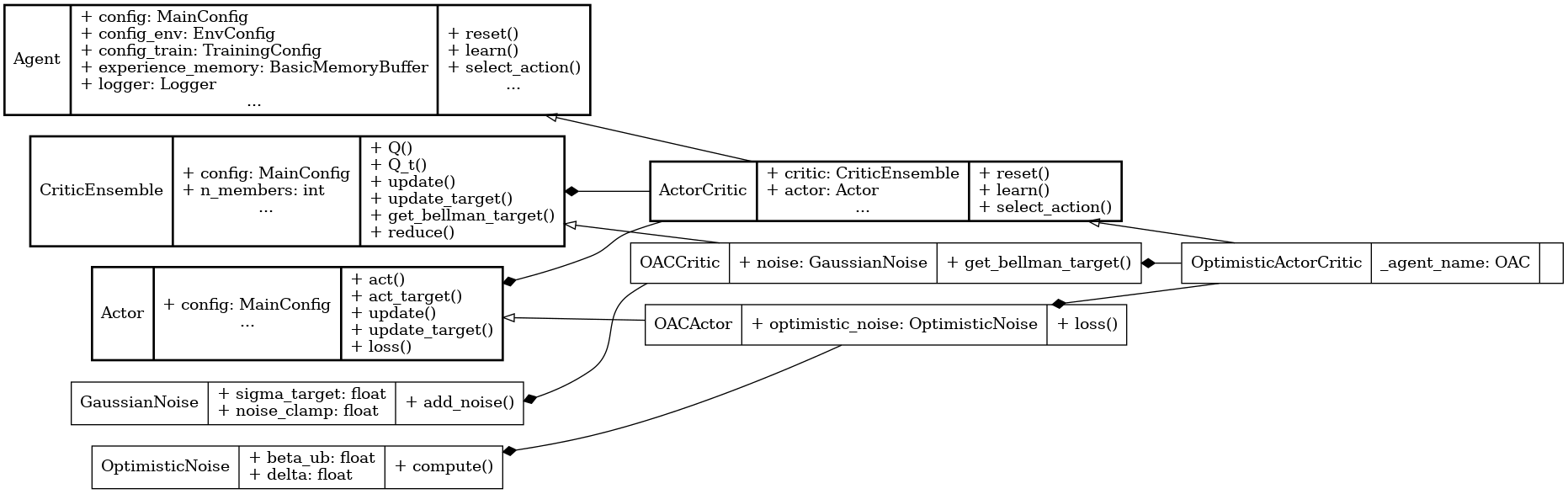
UML diagram for the OAC algorithm.#
We use the UML diagram to illustrate the relationships between the classes in our OAC implementation.
The diagram shows how the OACActor and OACCritic classes inherit from the base classes Actor and CriticEnsemble, respectively. OptimisticActorCritic class also inherits from ActorCritic class which inherits from Agent.
We illustrate each class's crucial attributes and methods for OAC. Specifically:
get_bellman_target() method in OACCritic class is implemented to compute the Bellman target using actions perturbed by Gaussian noise, following the TD3-style target smoothing.
OptimisticNoise class is introduced to compute exploration noise by adjusting the mean of the actor's action distribution in the direction of the Q-value upper confidence bound.
select_action() method in OptimisticActorCritic class is modified to optionally use the optimistic mean for exploration, enabling uncertainty-aware policy execution.
Classes#
- class objectrl.models.oac.OptimisticNoise(beta_ub: float, delta: float)[source]#
Bases:
objectComputes optimistic exploration noise as described in the OAC algorithm.
- beta_ub#
Coefficient on standard deviation of Q-values.
- Type:
float
- delta#
Exploration confidence parameter.
- Type:
float
- compute(state: Tensor, critics: CriticEnsemble, transformed_dist: TransformedDistribution) dict[source]#
Computes the optimistic adjustment to the mean of the action distribution.
- Parameters:
state (Tensor) – Input state tensor.
critics (CriticEnsemble) – Critic ensemble to evaluate Q-values.
transformed_dist (TransformedDistribution) – Tanh-transformed distribution from actor.
- Returns:
Contains adjusted mean (‘mu_e’) and scale (‘scale’) of the new action distribution.
- Return type:
dict
- class objectrl.models.oac.GaussianNoise(sigma_target=0, noise_clamp=0.15)[source]#
Bases:
objectAdds Gaussian noise to actions, used for target value perturbation in critic updates.
- sigma_target#
Standard deviation of the noise.
- Type:
float
- noise_clamp#
Value to clamp the noise between [-noise_clamp, noise_clamp].
- Type:
float
- class objectrl.models.oac.OACActor(config: MainConfig, dim_state: int, dim_act: int)[source]#
Bases:
ActorOAC-specific actor class with optimistic noise-based exploration.
Inherits from a base probabilistic actor, and modifies the loss function to incorporate upper-confidence bounds via Q-value ensembles.
- Parameters:
config (MainConfig) – Global configuration.
dim_state (int) – Dimensionality of observation space.
dim_act (int) – Dimensionality of action space.
- optimist_noise#
Instance to compute optimistic exploration noise.
- Type:
- __init__(config: MainConfig, dim_state: int, dim_act: int)[source]#
Initializes the Actor.
- Parameters:
config (MainConfig) – Configuration dataclass instance.
dim_state (int) – Dimension of observation space.
dim_act (int) – Dimension of action space.
- Returns:
None
- loss(state: Tensor, critics: CriticEnsemble) Tensor[source]#
Computes the actor loss using the mean Q-value.
- Parameters:
state (Tensor) – Input states.
critics (CriticEnsemble) – Critic networks.
- Returns:
Scalar loss value.
- Return type:
Tensor
- class objectrl.models.oac.OACCritic(config: MainConfig, dim_state: int, dim_act: int)[source]#
Bases:
CriticEnsembleOAC-specific critic ensemble class, adds Gaussian noise to actions for more robust target computation.
- Parameters:
config (MainConfig) – Global configuration.
dim_state (int) – Dimensionality of state space.
dim_act (int) – Dimensionality of action space.
- __init__(config: MainConfig, dim_state: int, dim_act: int)[source]#
Initialize the critic ensemble.
- Parameters:
config (MainConfig) – Configuration object with model parameters.
dim_state (int) – Dimension of the state space.
dim_act (int) – Dimension of the action space.
- Returns:
None
- get_bellman_target(reward: Tensor, next_state: Tensor, done: Tensor, actor: OACActor) Tensor[source]#
Computes the Bellman target for TD learning using noisy next actions.
- Parameters:
reward (Tensor) – Reward signal.
next_state (Tensor) – Next state input.
done (Tensor) – Episode termination flags.
actor (OACActor) – Actor used to compute next action.
- Returns:
Bellman target values.
- Return type:
Tensor
- class objectrl.models.oac.OptimisticActorCritic(config: MainConfig, critic_type: type = <class 'objectrl.models.oac.OACCritic'>, actor_type: type = <class 'objectrl.models.oac.OACActor'>)[source]#
Bases:
ActorCriticOAC agent class that integrates the OAC actor and critic. Ciosek et al. (2019): Better Exploration with Optimistic Actor-Critic
- _agent_name = 'OAC'#
- __init__(config: MainConfig, critic_type: type = <class 'objectrl.models.oac.OACCritic'>, actor_type: type = <class 'objectrl.models.oac.OACActor'>) None[source]#
Initializes the OAC agent.
- Parameters:
config (MainConfig) – Configuration dataclass instance.
critic_type (type) – Critic class type.
actor_type (type) – Actor class type.
- Returns:
None
- select_action(state: Tensor, is_training: bool = True) Tensor[source]#
Selects an action given a state, optionally applying optimistic exploration.
- Parameters:
state (Tensor) – Input state tensor.
is_training (bool) – If True, applies optimistic exploration noise.
- Returns:
Action to execute in the environment.
- Return type:
Tensor