Deep Exploration with PAC-Bayes (PBAC)#
PAC-Bayes exploration uncertainty estimationPaper: Deep Exploration with PAC-Bayes
Pseudocode#
Configuration#
@dataclass
class CriticLossConfig:
"""
Configuration for the PAC-Bayesian critic loss.
Attributes:
complexity_coef (float): Weight of the complexity term in the loss.
prior_variance (float): Prior variance used in KL divergence computation.
bootstrap_rate (float): Rate for masking samples during loss computation.
logvar_lower_clamp (float): Minimum value to clamp log variance to.
logvar_upper_clamp (float): Maximum value to clamp log variance to.
gamma (float): Discount factor for Bellman target.
sig2_lowerclamp (float): Minimum variance to avoid division by zero.
reduction (Literal): Type of loss reduction ('mean', 'sum', or 'none').
"""
complexity_coef: float = 0.01
prior_variance: float = 1.0
bootstrap_rate: float = 0.05
logvar_lower_clamp: float = 0.01
logvar_upper_clamp: float = 100.0
gamma: float = 0.99
sig2_lower_clamp: float = 1e-6
reduction: Literal["mean", "sum", "none"] = "mean"
@dataclass
class PBACActorConfig:
"""
Configuration for the PBAC Actor network.
Attributes:
arch (type): Actor architecture class.
actor_type (type): Actor class to use (PBACActor).
has_target (bool): Whether to use a target actor network.
n_heads (int): Number of actor output heads (for ensemble policy).
"""
arch: type = ActorNetProbabilistic
actor_type: type = PBACActor
has_target: bool = False
n_heads: int = 10
@dataclass
class PBACCriticConfig:
"""
Configuration for the PBAC Critic ensemble.
Attributes:
arch (type): Critic network architecture.
critic_type (type): Critic implementation class.
n_members (int): Number of critics in the ensemble.
"""
arch: type = CriticNet
critic_type: type = PBACCritic
n_members: int = 10
@dataclass
class PBACConfig:
"""
Top-level configuration for the PBAC agent.
Attributes:
name (str): Agent name identifier.
lossparams (CriticLossConfig): Configuration for critic loss function.
target_entropy (float or None): Target entropy for policy regularization.
loss (str): Name of the loss function.
policy_delay (int): Number of critic updates per actor update.
tau (float): Polyak averaging coefficient for target updates.
posterior_sampling_rate (int): Frequency to resample actor ensemble index.
alpha (float): Entropy temperature.
actor (PBACActorConfig): Actor configuration.
critic (PBACCriticConfig): Critic configuration.
"""
name: str = "pbac"
lossparams: CriticLossConfig = field(default_factory=CriticLossConfig)
target_entropy: float | None = None
loss: str = "PACBayesLoss"
policy_delay: int = 1
tau: float = 0.005
posterior_sampling_rate: int = 5
alpha: float = 1.0
actor: PBACActorConfig = field(default_factory=PBACActorConfig)
critic: PBACCriticConfig = field(default_factory=PBACCriticConfig)
def __post_init__(self):
if isinstance(self.lossparams, dict):
self.lossparams = CriticLossConfig(**self.lossparams)
UML Diagram#
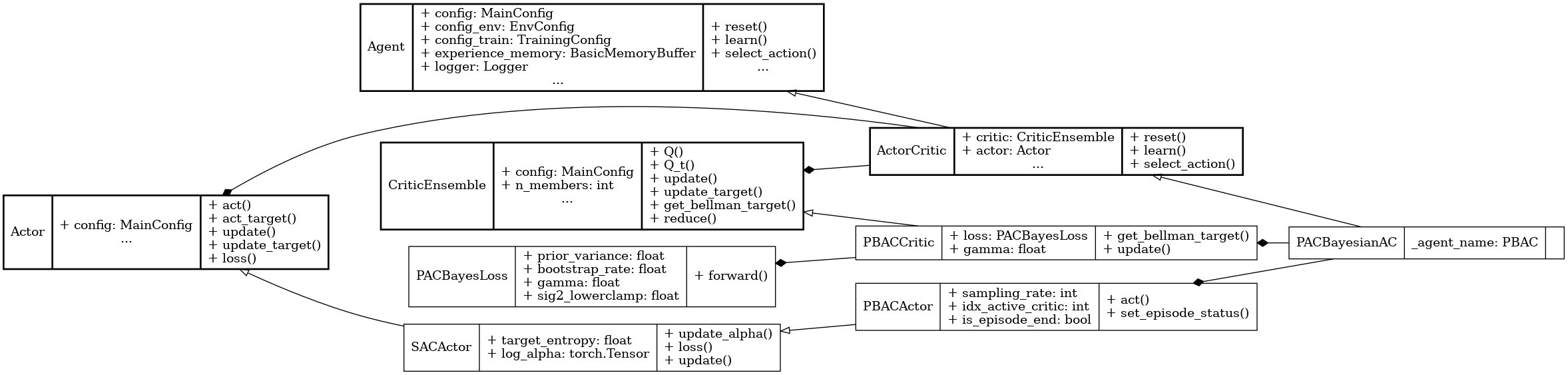
UML diagram for the PBAC algorithm.#
We use the UML diagram to illustrate the relationships between the classes in our PBAC implementation.
The diagram shows how the PBACActor and PBACCritic classes inherit from the base classes SACActor and CriticEnsemble, respectively. PACBayesianAC class also inherits from ActorCritic class which inherits from Agent.
We illustrate each class's crucial attributes and methods for PBAC. Specifically:
PACBayesLoss class implements a custom critic loss that incorporates a PAC-Bayesian generalization bound with a bootstrap-based variance estimate to account for uncertainty.
get_bellman_target() method in PBACCritic class is implemented to compute entropy-regularized targets using the actor’s log probability.
PBACActor class overrides the act() method to support posterior sampling by randomly selecting a head from the ensemble at training time or averaging actions at evaluation time.
Classes#
- class objectrl.models.pbac.PBACActor(config: MainConfig, dim_state: int, dim_act: int)[source]#
Bases:
SACActorActor class for PBAC with posterior sampling-based ensemble head selection.
- Parameters:
config (MainConfig) – Configuration object.
dim_state (int) – Observation space dimensions.
dim_act (int) – Action space dimensions.
Samples a head from an ensemble of actor policies every N steps or at episode boundaries to simulate posterior sampling. At evaluation time, it averages actions.
- __init__(config: MainConfig, dim_state: int, dim_act: int) None[source]#
Initializes the Actor.
- Parameters:
config (MainConfig) – Configuration dataclass instance.
dim_state (int) – Dimension of observation space.
dim_act (int) – Dimension of action space.
- Returns:
None
- act(state: Tensor, is_training: bool = True) dict[source]#
Selects an action, potentially sampling from different actor heads during training.
- Parameters:
state (Tensor) – Current observation.
is_training (bool) – Whether in training mode.
- Returns:
Action dictionary with ‘action’ and ‘action_logprob’.
- Return type:
dict
- class objectrl.models.pbac.PBACCritic(config: MainConfig, dim_state: int, dim_act: int)[source]#
Bases:
CriticEnsemblePBAC critic ensemble using PAC-Bayesian loss.
- Parameters:
config (MainConfig) – Configuration object.
dim_state (int) – State space dimensions.
dim_act (int) – Action space dimensions.
Implements target computation and weight updates using the PAC-Bayesian loss.
- __init__(config: MainConfig, dim_state: int, dim_act: int) None[source]#
Initialize the critic ensemble.
- Parameters:
config (MainConfig) – Configuration object with model parameters.
dim_state (int) – Dimension of the state space.
dim_act (int) – Dimension of the action space.
- Returns:
None
- get_bellman_target(reward: Tensor, next_state: Tensor, done: Tensor, actor: PBACActor) Tensor[source]#
Computes target Q-values using entropy-regularized Bellman backup.
- Parameters:
reward (Tensor) – Rewards.
next_state (Tensor) – Next states.
done (Tensor) – Done flags.
actor (PBACActor) – Actor network for next state action selection.
- Returns:
Bellman targets.
- Return type:
Tensor
- class objectrl.models.pbac.PACBayesianAC(config: MainConfig, critic_type: type = <class 'objectrl.models.pbac.PBACCritic'>, actor_type: type = <class 'objectrl.models.pbac.PBACActor'>)[source]#
Bases:
ActorCriticPBAC agent class implementing PAC-Bayesian Actor-Critic logic. Combines the PBACActor and PBACCritic, manages training and interaction. Tasdighi et al. (2025): Deep Exploration with PAC-Bayes
- _agent_name = 'PBAC'#
- __init__(config: MainConfig, critic_type: type = <class 'objectrl.models.pbac.PBACCritic'>, actor_type: type = <class 'objectrl.models.pbac.PBACActor'>) None[source]#
Initializes the PBAC agent.
- Parameters:
config (MainConfig) – Configuration dataclass instance.
critic_type (type) – Critic class type.
actor_type (type) – Actor class type.
- Returns:
None