Twin Delayed DDPG (TD3)#
off-policy deterministic twin-critics delayed-updatePaper: Addressing Function Approximation Error in Actor-Critic Methods
Pseudocode#
Configuration#
@dataclass
class ActorNoiseConfig:
"""
Configuration for noise added to actor actions in TD3.
Attributes:
policy_noise (float): Std dev of noise added during training.
target_policy_noise (float): Std dev of noise added to target policy actions.
target_policy_noise_clip (float): Clipping range for target policy noise.
"""
policy_noise: float = 0.1
target_policy_noise: float = 0.2
target_policy_noise_clip: float = 0.5
@dataclass
class TD3ActorConfig:
"""
Configuration for the TD3 actor network.
Attributes:
arch (type): Actor network architecture class.
actor_type (type): Actor class type.
has_target (bool): Whether the actor has a target network.
"""
arch: type = ActorNet
actor_type: type = TD3Actor
has_target: bool = True
@dataclass
class TD3CriticConfig:
"""
Configuration for the TD3 critic network ensemble.
Attributes:
arch (type): Critic network architecture class.
critic_type (type): Critic class type.
"""
arch: type = CriticNet
critic_type: type = TD3Critic
@dataclass
class TD3Config:
"""
Main TD3 algorithm configuration.
Attributes:
name (str): Algorithm identifier.
noise (ActorNoiseConfig): Noise parameters for exploration.
loss (str): Loss function for critic training.
policy_delay (int): Number of critic updates per actor update.
tau (float): Polyak averaging coefficient for target network updates.
actor (TD3ActorConfig): Actor network configuration.
critic (TD3CriticConfig): Critic network configuration.
"""
name: str = "td3"
noise: ActorNoiseConfig = field(default_factory=ActorNoiseConfig)
loss: str = "MSELoss"
policy_delay: int = 2
tau: float = 0.005
actor: TD3ActorConfig = field(default_factory=TD3ActorConfig)
critic: TD3CriticConfig = field(default_factory=TD3CriticConfig)
def __post_init__(self):
if isinstance(self.noise, dict):
self.noise = ActorNoiseConfig(**self.noise)
UML Diagram#
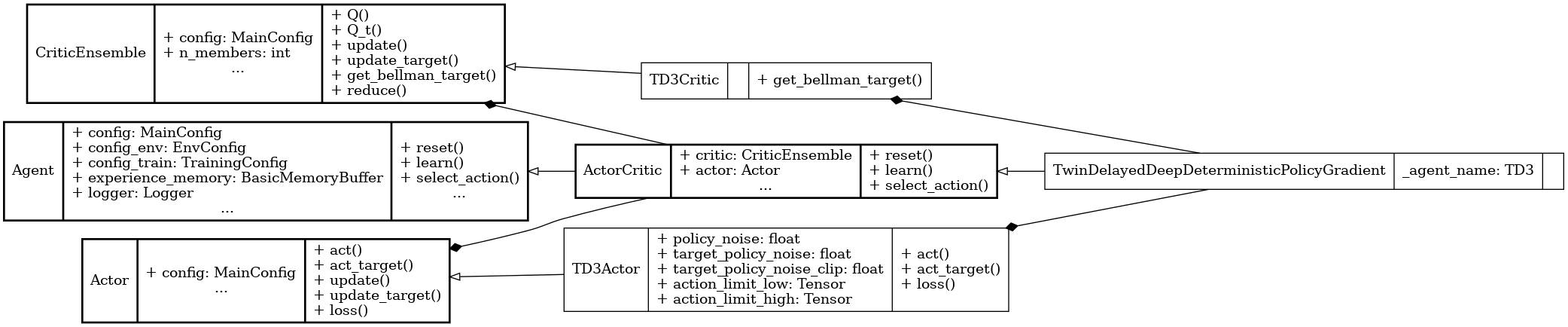
UML diagram for the TD3 algorithm.#
We use the UML diagram to illustrate the relationships between the classes in our TD3 implementation.
The diagram shows how the TD3Actor and TD3Critic classes inherit from the base classes Actor and CriticEnsemble, respectively. TwinDelayedDeepDeterministicPolicyGradient class also inherits from ActorCritic class which inherits from Agent.
We illustrate each class's crucial attributes and methods for TD3. Specifically:
get_bellman_target() method in TD3Critic class is implemented to compute the Bellman target for the critic in TD3 style.
act(), act_target(), and loss() methods in TD3Actor class are implemented to act in TD3 style and update the actor's policy.
Classes#
- class objectrl.models.td3.TD3Actor(config: MainConfig, dim_state: int, dim_act: int)[source]#
Bases:
ActorTD3 actor network with action noise for exploration and target policy smoothing.
- Parameters:
config (MainConfig) – Configuration object.
dim_state (int) – Observation space dimensions.
dim_act (int) – Action space dimensions.
- policy_noise#
Noise std for exploration.
- Type:
float
- target_policy_noise#
Noise std for target policy smoothing.
- Type:
float
- target_policy_noise_clip#
Clipping range for target noise.
- Type:
float
- action_limit_low#
Lower bound for actions.
- Type:
Tensor
- action_limit_high#
Upper bound for actions.
- Type:
Tensor
- __init__(config: MainConfig, dim_state: int, dim_act: int) None[source]#
Initializes the Actor.
- Parameters:
config (MainConfig) – Configuration dataclass instance.
dim_state (int) – Dimension of observation space.
dim_act (int) – Dimension of action space.
- Returns:
None
- act(state: Tensor, is_training: bool = True) dict[source]#
Computes actions with optional noise added for exploration.
- Parameters:
state (Tensor) – Batch of states.
is_training (bool) – Whether in training mode (adds noise if True).
- Returns:
Contains ‘action’ tensor and ‘action_wo_noise’ tensor.
- Return type:
dict
- act_target(state: Tensor) dict[source]#
Computes target policy action with smoothing noise added.
- Parameters:
state (Tensor) – Batch of next states.
- Returns:
Contains ‘action’ tensor with added clipped noise.
- Return type:
dict
- loss(state: Tensor, critics: CriticEnsemble) Tensor[source]#
Computes actor loss as negative Q-value estimate.
- Parameters:
state (Tensor) – Batch of states.
critics (CriticEnsemble) – Critic networks.
- Returns:
Actor loss to maximize Q-values.
- Return type:
Tensor
- class objectrl.models.td3.TD3Critic(config: MainConfig, dim_state: int, dim_act: int)[source]#
Bases:
CriticEnsembleTD3 critic ensemble handling Bellman target computation and training loss.
- Parameters:
config (MainConfig) – Configuration object.
dim_state (int) – Observation space dimensions.
dim_act (int) – Action space dimensions.
- __init__(config: MainConfig, dim_state: int, dim_act: int) None[source]#
Initialize the critic ensemble.
- Parameters:
config (MainConfig) – Configuration object with model parameters.
dim_state (int) – Dimension of the state space.
dim_act (int) – Dimension of the action space.
- Returns:
None
- get_bellman_target(reward: Tensor, next_state: Tensor, done: Tensor, actor: TD3Actor) Tensor[source]#
Computes target Q-values using Bellman backup.
- Parameters:
reward (Tensor) – Rewards batch.
next_state (Tensor) – Next state batch.
done (Tensor) – Done flags batch.
actor (TD3Actor) – Target policy actor network.
- Returns:
Bellman target Q-values.
- Return type:
Tensor
- class objectrl.models.td3.TwinDelayedDeepDeterministicPolicyGradient(config: MainConfig, critic_type: type = <class 'objectrl.models.td3.TD3Critic'>, actor_type: type = <class 'objectrl.models.td3.TD3Actor'>)[source]#
Bases:
ActorCriticTD3 agent combining delayed policy updates and clipped noise target smoothing. Fujimoto et al. (2018): Addressing Function Approximation Error in Actor-Critic Methods
- _agent_name = 'TD3'#
- __init__(config: MainConfig, critic_type: type = <class 'objectrl.models.td3.TD3Critic'>, actor_type: type = <class 'objectrl.models.td3.TD3Actor'>) None[source]#
Initializes the TD3 agent.
- Parameters:
config (MainConfig) – Configuration dataclass instance.
critic_type (type) – Critic class type.
actor_type (type) – Actor class type.
- Returns:
None