Proximal Policy Optimization (PPO)#
on-policy policy optimization clippingPaper: Proximal Policy Optimization Algorithms
Pseudocode#
Configuration#
@dataclass
class PPOActorConfig:
"""
Configuration for the PPO actor network.
Attributes:
arch (type): The architecture class to be used for the actor network.
actor_type (type): The class implementing the PPO actor logic.
has_target (bool): Whether to maintain a target network for the actor.
width (int): Width of hidden layers in the actor network.
max_grad_norm (float): Maximum norm for gradient clipping in the actor.
"""
arch: type = PPOActorNetProbabilistic
actor_type: type = PPOActor
has_target: bool = False
width: int = 64
max_grad_norm: float = 0.5
@dataclass
class PPOCriticConfig:
"""
Configuration for the PPO critic network.
Attributes:
arch (type): The architecture class to be used for the critic network.
critic_type (type): The class implementing the PPO critic logic.
has_target (bool): Whether to maintain a target network for the critic.
n_members (int): Number of ensemble members in the critic network.
width (int): Width of hidden layers in the critic network.
max_grad_norm (float): Maximum norm for gradient clipping in the critic.
"""
arch: type = ValueNet
critic_type: type = PPOCritic
has_target: bool = False
n_members: int = 1
width: int = 64
max_grad_norm: float = 0.5
@dataclass
class PPOConfig:
"""
Full configuration for a PPO agent, including actor, critic, and optimization hyperparameters.
Attributes:
name (str): Identifier name for the PPO configuration.
loss (str): Name of the loss function to use (e.g., 'MSELoss').
tau (float): Polyak averaging coefficient for target network updates.
policy_delay (int): Delay interval between policy (actor) updates.
max_grad_norm (float): Maximum norm for gradient clipping globally.
clip_rate (float): Clipping factor for the PPO objective.
GAE_lambda (float): Lambda parameter for Generalized Advantage Estimation.
normalize_advantages (bool): Whether to normalize advantages during training.
entropy_coef (float): Coefficient for entropy regularization.
actor (PPOActorConfig): Configuration object for the PPO actor.
critic (PPOCriticConfig): Configuration object for the PPO critic.
"""
name: str = "ppo"
loss: str = "MSELoss"
tau: float = 0.0
policy_delay: int = 1
max_grad_norm: float = 0.5
clip_rate: float = 0.2
GAE_lambda: float = 0.95
normalize_advantages: bool = True
entropy_coef: float = 0.0
actor: PPOActorConfig = field(default_factory=PPOActorConfig)
critic: PPOCriticConfig = field(default_factory=PPOCriticConfig)
UML Diagram#
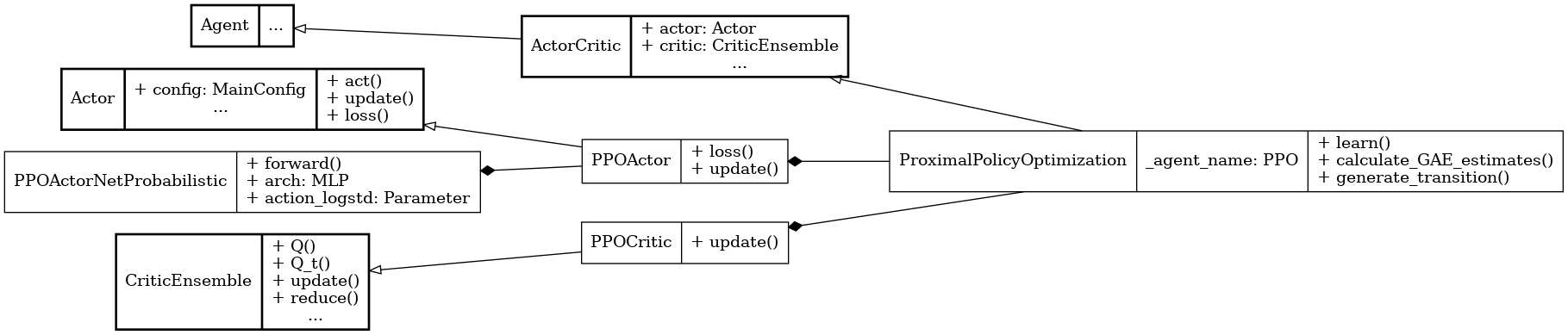
UML diagram for the PPO algorithm.#
We use the UML diagram to illustrate the relationships between the classes in our PPO implementation.
The diagram shows how the PPOActor and PPOCritic classes inherit from the base classes Actor and CriticEnsemble, respectively. ProximalPolicyOptimization class also inherits from ActorCritic class which inherits from Agent.
We illustrate each class's crucial attributes and methods for PPO. Specifically:
PPOActorNetProbabilistic class implements a probabilistic actor network with Gaussian policies for continuous actions.
loss() and update() methods in PPOActor class implement the PPO clipped surrogate objective and actor updates.
update() method in PPOCritic class updates the critic using Bellman targets computed externally.
ProximalPolicyOptimization class handles the overall training loop including generalized advantage estimation (GAE) and batched updates.
Classes#
- class objectrl.models.ppo.PPOActorNetProbabilistic(dim_state: int, dim_act: int, n_heads: int = 1, depth: int = 3, width: int = 256, act: Literal['crelu', 'relu'] = 'relu', has_norm: bool = False, upper_clamp: float = -1.0)[source]#
Bases:
ModuleProbabilistic actor network for PPO using a Gaussian policy.
- Parameters:
dim_state (int) – Dimension of input state.
dim_act (int) – Dimension of action space.
n_heads (int) – Number of heads (only supports 1).
depth (int) – Depth of the MLP.
width (int) – Width of each MLP layer.
act (Literal["crelu", "relu"]) – Activation function.
has_norm (bool) – Whether to include normalization layers.
upper_clamp (float) – Maximum clamp value for log standard deviation.
- __init__(dim_state: int, dim_act: int, n_heads: int = 1, depth: int = 3, width: int = 256, act: Literal['crelu', 'relu'] = 'relu', has_norm: bool = False, upper_clamp: float = -1.0) None[source]#
Initialize internal Module state, shared by both nn.Module and ScriptModule.
- forward(x: Tensor, is_training: bool = True) dict[source]#
Forward pass to generate actions and log probabilities.
- Parameters:
x (torch.Tensor) – Input state tensor.
is_training (bool) – Whether to sample or return mode.
- Returns:
Dictionary containing action distribution, action, and log-prob.
- Return type:
dict
- class objectrl.models.ppo.PPOActor(config: MainConfig, dim_state: int, dim_act: int)[source]#
Bases:
ActorPPO Actor implementation.
- Parameters:
config (MainConfig) – Configuration object.
dim_state (int) – Dimension of state space.
dim_act (int) – Dimension of action space.
- __init__(config: MainConfig, dim_state: int, dim_act: int) None[source]#
Initializes the Actor.
- Parameters:
config (MainConfig) – Configuration dataclass instance.
dim_state (int) – Dimension of observation space.
dim_act (int) – Dimension of action space.
- Returns:
None
- loss(state: Tensor, actions: Tensor, action_logprob: Tensor, advantages: Tensor) Tensor[source]#
Calculates the PPO clipped surrogate loss.
- Parameters:
state (torch.Tensor) – State input.
actions (torch.Tensor) – Actions taken.
action_logprob (torch.Tensor) – Old log-probs of actions.
advantages (torch.Tensor) – Advantage estimates.
- Returns:
Computed loss.
- Return type:
torch.Tensor
- update(state: Tensor, actions: Tensor, action_logprob: Tensor, advantages: Tensor) None[source]#
Performs gradient update on the actor network.
- Parameters:
state (torch.Tensor) – Input state batch.
actions (torch.Tensor) – Sampled actions.
action_logprob (torch.Tensor) – Log-probs of sampled actions.
advantages (torch.Tensor) – Advantage estimates.
- class objectrl.models.ppo.PPOCritic(config: MainConfig, dim_state: int, dim_act: int)[source]#
Bases:
CriticEnsemblePPO Critic using an ensemble of Q-value estimators.
- Parameters:
config (MainConfig) – Configuration object.
dim_state (int) – State dimension.
dim_act (int) – Action dimension.
- __init__(config: MainConfig, dim_state: int, dim_act: int)[source]#
Initialize the critic ensemble.
- Parameters:
config (MainConfig) – Configuration object with model parameters.
dim_state (int) – Dimension of the state space.
dim_act (int) – Dimension of the action space.
- Returns:
None
- class objectrl.models.ppo.ProximalPolicyOptimization(config: MainConfig, critic_type: type = <class 'objectrl.models.ppo.PPOCritic'>, actor_type: type = <class 'objectrl.models.ppo.PPOActor'>)[source]#
Bases:
ActorCriticPPO agent that handles actor-critic updates, GAE estimation and learning. Schulman et al. (2017): Proximal Policy Optimization Algorithms
- _agent_name = 'PPO'#
- __init__(config: MainConfig, critic_type: type = <class 'objectrl.models.ppo.PPOCritic'>, actor_type: type = <class 'objectrl.models.ppo.PPOActor'>) None[source]#
Initializes the PPO agent.
- Parameters:
config (MainConfig) – Configuration dataclass instance.
critic_type (type) – Critic class type.
actor_type (type) – Actor class type.
- Returns:
None